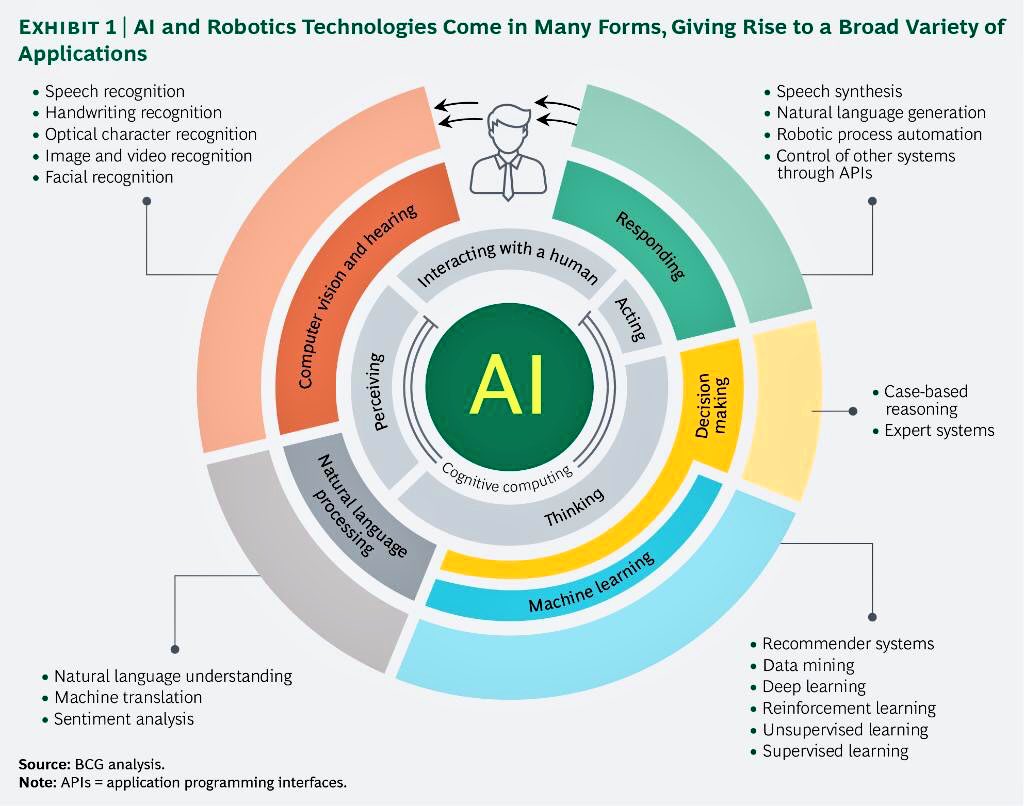
El miedo, la envidia y la fantasia son tres palancas clave para el progreso de nuestra especie desde la revolución cognitiva ocurrida hace unos 70 mil años. Con miedo, envidia y fantasía nuestra especie no sólo consiguió expandir el alcance de sus genes más allá de otras muchas especies, sino que impusimos nuestros memes y temes para aumentar nuestra eficiencia.

Ahora estamos asistiendo a una revolución del mismo calibre que la que ocurrió en Africa. Pero nos cuesta identificarla porque estamos demasiado próximos a los árboles.
En cualquier caso, el miedo, la envidia y la fantasía continúan siendo los tres argumentos usados a favor y en contra de la IA.
Y esto es lo que responde #ChatGPT cuando le pregunto «¿Por qué tienen miedo los humanos a la inteligencia artificial?
El miedo humano hacia la inteligencia artificial (IA) puede atribuirse a varias razones:
– Temor a lo desconocido: La IA es un campo en constante evolución y desarrollo, y gran parte de su potencial aún no se ha explorado por completo. – – La falta de comprensión sobre cómo funciona exactamente la IA y cómo podría impactar diversas áreas de la vida puede generar temor e incertidumbre.
– Representación en medios y cultura popular: En películas, libros y otros medios de entretenimiento, a menudo se presenta a la IA como una fuerza descontrolada y amenazante que puede superar a la humanidad. Estas representaciones exageradas pueden influir en la percepción pública y generar miedo hacia la IA.
– Pérdida de control: Existe el temor de que la IA pueda superar o reemplazar a los seres humanos en diversas tareas y roles, lo que lleva a preocupaciones sobre la pérdida de empleos y la falta de autonomía humana. La idea de depender demasiado de las máquinas y perder el control sobre nuestras propias vidas puede generar ansiedad.
– Ética y responsabilidad: A medida que la IA se vuelve más sofisticada, surgen preguntas éticas y morales sobre su uso y sus implicaciones. El temor radica en la posibilidad de que la IA pueda tomar decisiones que no sean éticas o actuar de manera perjudicial para la humanidad si no se establecen salvaguardias adecuadas.
– Riesgo existencial: Algunas personas temen que la IA pueda desarrollarse hasta el punto de superar la inteligencia humana y representar un riesgo existencial para la humanidad. La preocupación se centra en escenarios hipotéticos en los que la IA pueda volverse demasiado poderosa o descontrolada, lo que podría amenazar la supervivencia de nuestra especie.
Es importante tener en cuenta que el miedo hacia la IA no es universal y que también existen perspectivas optimistas sobre su potencial para mejorar la vida humana. La comprensión, el diálogo y la colaboración entre expertos en IA, ética, legisladores y la sociedad en general son fundamentales para abordar los temores legítimos y garantizar que la IA se desarrolle y utilice de manera responsable y beneficiosa para la humanidad.