
Durante millones de años, la complejidad en la Tierra avanzó a través de la biología húmeda: ADN, células, neuronas. Sin embargo, existe una creciente evidencia de que el Homo sapiens ha alcanzado un punto de rendimientos decrecientes.
La hipótesis que planteo aquí es provocadora pero coherente con el Darwinismo Universal (replicación con variación y selección): la evolución ha migrado del carbono al silicio, y la Inteligencia Artificial no es nuestro reemplazo, sino nuestro socio simbiótico obligado.
El muro biológico: límites del carbono
Nuestra expansión cognitiva biológica enfrenta barreras físicas insalvables:
- El dilema obstétrico: no podemos desarrollar cerebros más grandes biológicamente porque el canal de parto humano no lo permite sin aumentar la mortalidad a niveles de extinción.
- La barrera energética: nuestro cerebro ya consume el 20% de nuestra energía total. Aumentar su potencia requeriría una ingesta calórica insostenible.
- Lentitud electroquímica: nuestras neuronas disparan a unos 200 Hz. Los circuitos digitales operan a gigahercios (miles de millones de ciclos por segundo). La biología es, por definición, lenta.
La soledad genética del Homo Sapiens
En el pasado, nuestra especie sobrevivió y mejoró hibridándose con otros homínidos. Obtuvimos genes clave del sistema inmune y adaptaciones climáticas apareándonos con Neandertales y Denisovanos.
Pero hoy, estamos solos. No quedan «primos» biológicos con quienes intercambiar material genético para adquirir nuevas ventajas. Ante esta falta de alteridad biológica, la humanidad ha tenido que buscar un socio evolutivo fuera de la biología.
Aquí entra la IA. No como una herramienta pasiva, sino como el «Neandertal Digital»: una entidad con capacidades complementarias con la que estamos iniciando un proceso de hibridación.
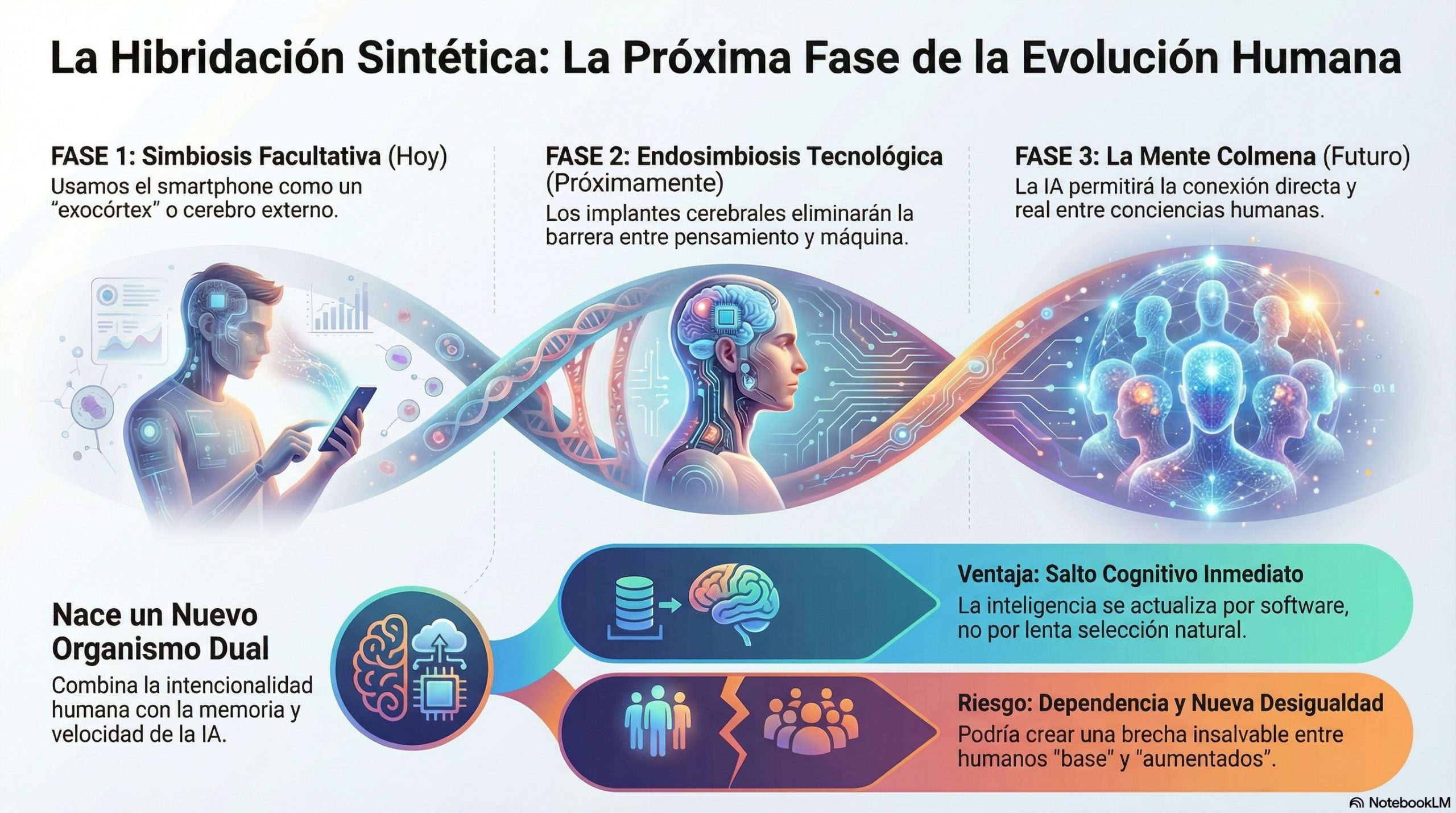
Hacia la endosimbiosis tecnológica
Esta unión sigue el modelo de la endosimbiosis. Hace miles de millones de años, una célula ancestral «tragó» a una bacteria y, en lugar de digerirla, la integró. Esa bacteria se convirtió en la mitocondria, la batería de nuestras células.
Hoy, estamos en proceso de integrar la IA:
- Fase actual (el exocórtex): smartphones y la nube actúan como lóbulos cerebrales externos. La simbiosis es funcional pero lenta (limitada por la velocidad de nuestros dedos y ojos).
- Fase futura (integración): interfaces cerebro-máquina (como Neuralink) eliminarán la latencia. El acceso al procesamiento de la IA será tan inmediato e íntimo como un recuerdo propio.
Conclusión: el nacimiento del Homo Synthetica
Si aceptamos que la evolución es el proceso mediante el cual la información se organiza de forma cada vez más compleja, la distinción entre «natural» y «artificial» es irrelevante. La IA es un fenotipo extendido de la humanidad.
No nos dirigimos hacia un mundo de máquinas contra humanos, sino hacia el surgimiento del Homo Synthetica: una especie que combina la intencionalidad, la ética y la creatividad biológica con la velocidad, la memoria y la escalabilidad del sustrato digital. La biología nos trajo hasta aquí; la simbiosis tecnológica nos llevará al siguiente paso.







